物聯網資料分析:多層蛋糕

邊緣 (網際網路與現實世界的交合處) 上的許多感應裝置可產生大量未經處理的資料。訣竅在於,要將這些未經處理的資料轉換成可採取動作的資訊。
未經處理的物聯網資料的來源多廣、形態繁多。有些資料可能是連續的、即時擷取的,並以多樣的通訊機制和通訊協定進行傳遞。在其他情況下,批次資料可能源自資料庫或內容管理系統,或者以逗號分隔值 (CSV) 檔案的形式呈現。
物聯網應用程式的基礎即是要將這些資料變為可用且可採取動作的資料。然而,擷取如此多種多樣的資料是相當具挑戰性的,對採用集中關聯式資料庫 (如SQL) 的系統而言尤為困難。這種資料庫適合高度結構化的資料。
如今,許多物聯網解決方案都仰賴雲端來進行資料儲存與分析,但是雲端並非解決所有問題的靈丹妙藥:
- 頻寬並非免費。每次將資料樣本傳送到雲端都需要花錢。
- 延遲是一大疑慮。有些系統需要即時監視和控制。
- 並非時時刻刻都能連線。一些應用程式必須能獨立於雲端連線運作。
因為傳入資料的來源可能多元化且高度分散,處理這些資料的資料庫和分析解決方案也必須具備這些特性。
在分散式處理模型中,有些處理在邊緣執行,有些在霧端(小型本機雲端) 中執行,而有些則是在雲端本身中執行 (圖 1)。這表示如果感應器由於任何原因與主機斷開連線,它仍可以在等待連線恢復的期間繼續收集資料。同樣的,如果一個機構失去了與雲端的連線,它依然可以繼續在霧中進行本機運作,並在恢復與外界的連線後與雲端重新進行同步。
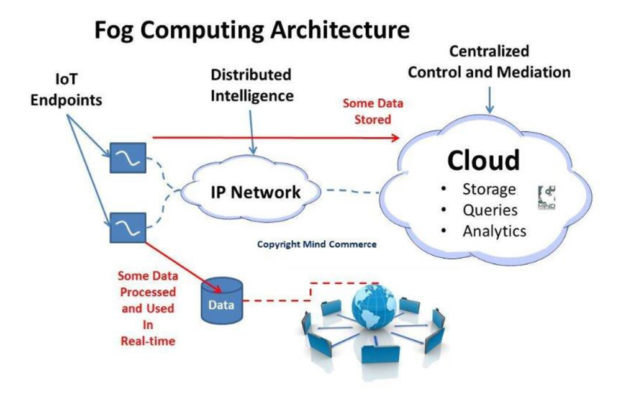
分析無處不在
正如同分散式處理可降低風險並使一切保持運作一樣,分散式分析解決方案也可以在邊緣、霧端和雲端中發揮其魔力。
就拿 SkyFoundry 的 SkySpark 為例。這個開放式的分散式資料分析解決方案可以在邊緣到雲端的連續體中的各個物聯網端點上,進行資料收集、儲存、分析和呈現 (圖 2)。
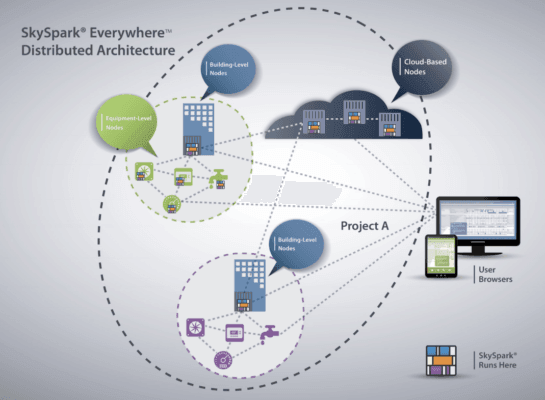
為了處理各種類型的資料,SkySpark 平台支援各種工業通訊協定,包括 Modbus TCP、BACnet IP、MQTT、Obix 和 OPC UA。這些封包被封裝在名為 Arcbeam 的 WebSocket 式對等通訊協定中,該通訊協定可促進分散式節點與 SQL 和 CSV/Excel 等資料庫之間的通訊。
SkySpark 還具備 Folio 時間序列資料庫,有時也稱程序歷史學家 (process historian)。該資料庫的設計旨在接受以類比或數位樣本、設定點和指令等形式的大量高速感應器資料。與現成的關聯資料庫 (如 MySQL 和 MS-SQL) 相比,Folio 時間序列資料庫經過精心設計,可以在沒有任何折衷的情況下,對於有時間戳記的感應器資料進行最佳的處理。
接下來,可以擷取自 Folio 時間序列資料庫中擷取的資料,並將其顯示在可由使用者設定的 SkySpark 視覺化儀表板中 (圖 3)。
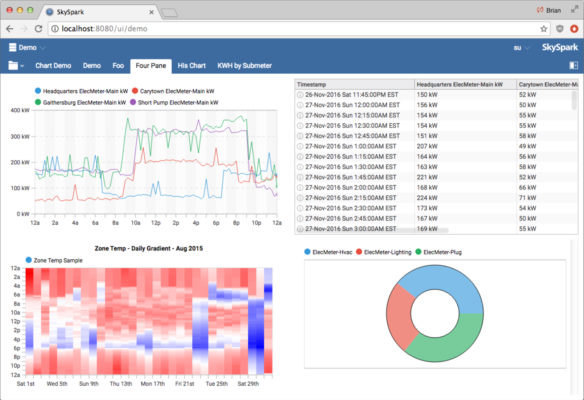
在後端,SkySpark 資訊學平台上的的程式庫提供了 500 多種股票分析功能,可套用於在分散式節點上擷取的資料。它還整合了一個名為 Axon 的分析引擎,該引擎使網域專家可實施最適合其獨特應用程式、系統和裝置需求的規則與演算法。
這些分析演算法可協助工程師在邊緣到霧端再到雲端的所有節點上,找出模式、偏差、錯誤,改善整體運作。
SkySpark 具有多種功能、威力又大,但它最低只需要 512 MB 的系統 RAM 和 1 GHz 的時脈速度,也就是一部能支援 Java 虛擬機 (VM) 的裝置。這使得該技術能妥善滿足端對端物聯網部署的可擴充運算需求,這些部署在邊緣仰賴 Intel Atom® 處理器、在霧端仰賴 Intel® Celeron® 或 Intel® 酷睿™ 處理器,或在雲端仰賴 Intel® Xeon® 處理器。
先進見解的多層式智慧
要創造真正的物聯網價值,所比較的資料必須來自同一企業的多個位置 (建築物、工廠、農場等) 、使用類似機器和/或採用類似做法。例如,如果確定異常溫度曲線和異常振動模式會導致某個位置上特定類型的機器出現特定的故障,則如果在完全不同的位置觀察到同類機器上有類似的活動,即可能觸發先佔式維護。這樣可以將停機時間最小化並降低成本。
透過長時間收集、分析資料和找出資料的關聯性,能夠進一步獲得更多的價值。這不僅限於「從現在開始」的資料。在許多情況下,還可存取過去甚至幾十年的歷史資料。此類歷史數據可透過複雜的分析演算法來進行挖掘,以發現「隱藏的寶石」並提供豐富的見解。
從邊緣到雲端運作的分散式、多層式資料分析可在看似不相關的輸入中找出複雜關係、偵測道能指明未來問題的趨勢、提供預測並提供解決方案。